一. 审题:
1.已知&输入:
- 给出一个长度为 L 的文本串。
- 给出 W 个单词串。
2.目标&输出:
- 在文本串中删除尽量少的字母使得文本串只有由词串构成,输出这个最少删除的字母数。
二. 思路
1. 思考解法
- 文本串后面的内容不会影响文本串前半部分的最优解,符合无后效性。
- 若把文本串右端位置作为状态,文本串右端位置较靠右的状态需要通过文本串右端位置较靠左的状态得到(如 di 需要通过 d0…di−1 的其中之一得到),符合子问题重叠性。
所以考虑DP。
2. 确定状态转移方程
di:前 i 个子母的文本串中最少删除的字母数。
txtidx:用该第 j 个单词串匹配前 i 个子母的文本串,匹配完时文本串的下标。(3. 中有详解)
delcnt:用该第 j 个单词串匹配前 i 个子母的文本串,匹配过程中失配的次数。(3. 中有详解)
seccessmatch:用该第 j 个单词串匹配前 i 个子母的文本串,是否匹配成功。(3. 中有详解)
综上所述,状转方程:di=minj=1W{di−1+1dtxtidx+delcnt(seccessmatch=false)(seccessmatch=true)
3.细节&详解
反正跟字符串有关题的题解,没图我是看不懂。
比如文本串是 cabbcxyz ,我们现在正在求 d5 (i=5) 用其中一个单词串 abc 匹配,用某个单词匹配时不用管其他单词。
初始时把 txtidx 设为 i (也就是 5),wordidx 设为单词长度, delcnt 设为 0 。(注意 delnum 不是整个文本串删去的字母个数,而是当前情况下匹配过部分的文本串的删去字母个数。3. 中有详解)
初始时:

第一次匹配后:
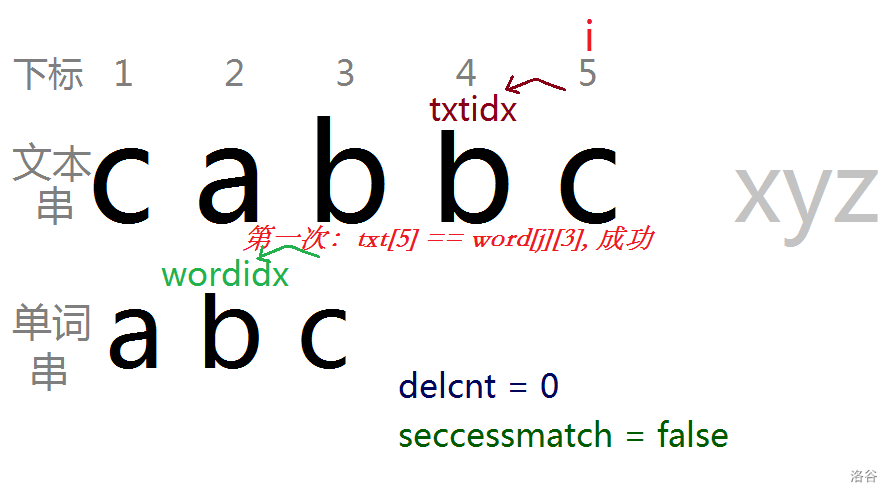
第二次匹配后:

第三次匹配后:

第四次匹配后:

三. 代码
代码中有比较详细的注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| #include<bits/stdc++.h>
using namespace std;
const int MAXwordcnt = 600;
const int MAXwordlen = 25;
const int MAXtxtlen = 300;
int wordcnt, txtlen;
char word[MAXwordcnt + 10][MAXwordlen + 10], txt[MAXtxtlen + 10];
int d[MAXtxtlen];
int main() {
scanf("%d %d", &wordcnt, &txtlen);
scanf("%s", txt + 1);
for (int i = 1; i <= wordcnt; ++i) {
scanf("%s", word[i] + 1);
}
d[0] = 0;
for (int i = 1; i <= txtlen; ++i) {
d[i] = d[i - 1] + 1;
for (int j = 1; j <= wordcnt; ++j) {
int wordidx = strlen(word[j] + 1);
int txtidx;
int delcnt = 0;
bool seccessmatch = 0;
for (txtidx = i; txtidx >= 1; --txtidx) {
if (wordidx == 0) {
seccessmatch = 1;
break;
}
if (txt[txtidx] == word[j][wordidx]) {
--wordidx;
} else {
++delcnt;
}
}
if (wordidx == 0) {
seccessmatch = 1;
}
if (seccessmatch) {
d[i] = min(d[i], d[txtidx] + delcnt);
}
}
}
printf("%d", d[txtlen]);
}
|